[popupwfancybox id=”6″]
Overview
The goal of the ICRC conference is to “discover and foster novel methodologies to reinvent computing technology, including new materials and physics, devices and circuits, system and network architectures, and algorithms and software”. The conference took place on the 5th floor of the Ritz-Carlton in McLean, VA. It was relatively small conference, about 200 in attendance, with two simultaneous sessions and talks focusing in general on neuromorphics, quantum computing and photonics. Naturally, Knowm Inc. was there and taking notes.
Wednesday Nov. 8
DARPA’s Vision for the Future of Computing
Dr. Hava Siegelmann (DARPA MTO)
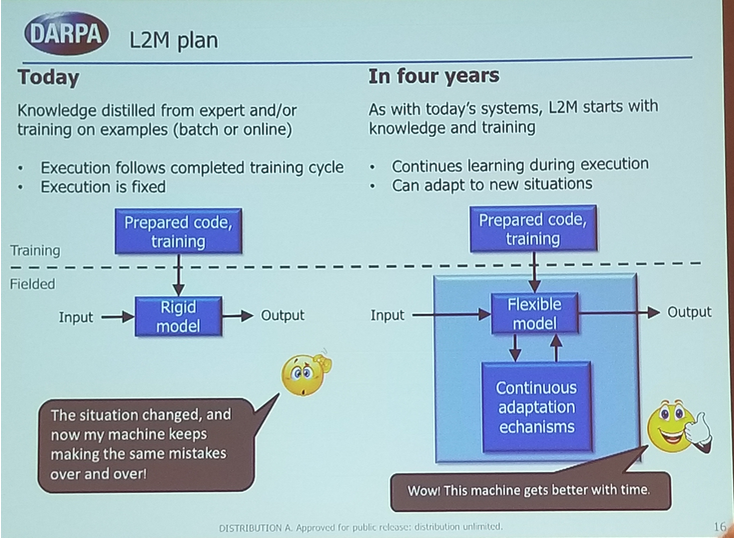
DARPA Life Long Learning Program ( L2M) Dr. Hava Siegelmann
- DoD considers AI/ML a strong tool. Countries are rushing to acquire ML, future security is dependent on it.
- Must think all the way through including fundamentals: software, hardware, materials, etc.
- Self-Driving cars, emphasized that accidents by Google, uber and telsa was not the car’s fault.
- AI is successful but brittle: We want rigor of automation with the flexibility of human.
- Catastrophic forgetting a big problem.
- LifeLongLearning Program: develop fundamentally new ML mechanisms that enable systems to improve their performance over their lifetimes.
- Adapt to new conditions is the big goal.
- “Develop with data from Afghanistan…deploy in Syria.”
- Current AI has two parts: (1) programs and rule, (2) parameter learning (ML)
- “Its not the strongest that survives; but…the one that is able to best to adapt..to the changing environment” L.C. Meginson, re “On the origin of the species”
- Nature’s mechanisms for change beyond preloaded programs:
- brain reconsolidating
- epigenetics
- Promoted her theoretical computer science book: “Neural Networks and Analog Computation“.
- Quoted Turing and pointed out that he did not see Turing machines as a basis for intelligent machines, instead he pointed to “unorganized machines”.
- “Electronic computers are intended to carry out any definite rule of thumb process…working in a disciplined but unintelligent manner” (emphasis hers)
- “My contention is that machine can be constructed that will simulate the behavior of the human mind”
- Nature combines Turing machines with super-Turing computation.
- adapt as needed, changing their Turing parameters.
- Lifelong Learning Program Plan
- Continual learning
- Adaptation to new tasks and circumstances
- Goal-driven perception
- Selective plasticity
- Safety and monitoring
- “We have already picked teams, but the way to join us is the “Center Group”
- Led by Government with one technical representative from each performer.
- Unclear how others can participate.

DARPA Life Long Learning Program ( L2M), Dr. Hava Siegelmann, Center Group
Continuously learning systems with high biological realism
Karlheinz Meier
- “Focus on finding the principles”
- “The ability to test models” is missing from neuroscience.
- Two fundamentally different modeling approaches:
- numerical models: params stored as binary numbers
- physical model: params as physical quantities (voltage, current, charge, etc)
- Emphasized the structural organization of the brain.
- local spatial integration–directionality–connectivity–hierarchy
- Emphasized time and temporal integration (STDP, sparse information coding via timing and time correlations, etc)
- Why use spikes: energy efficiency, scalability, computational advantages (to be proven)
- Emphasized that there are 7 to 11 orders of magnitude in space and time across various structures and temporal operation of brains.
- Comparison of digital and analog and mixed signal
- Mixed Signal: local analog computation
- Binary communication by spikes
- Signal restored in neuron (implies scalability)
- Neuromorphic implementations:
- In increasing biological realism: Spiknnaker–>IBM–>BrainScales
- Review of brainscales processing unit circuit, unit, whole system
- Attempted to do deep neural networks. Illustrated back propagation cycle.
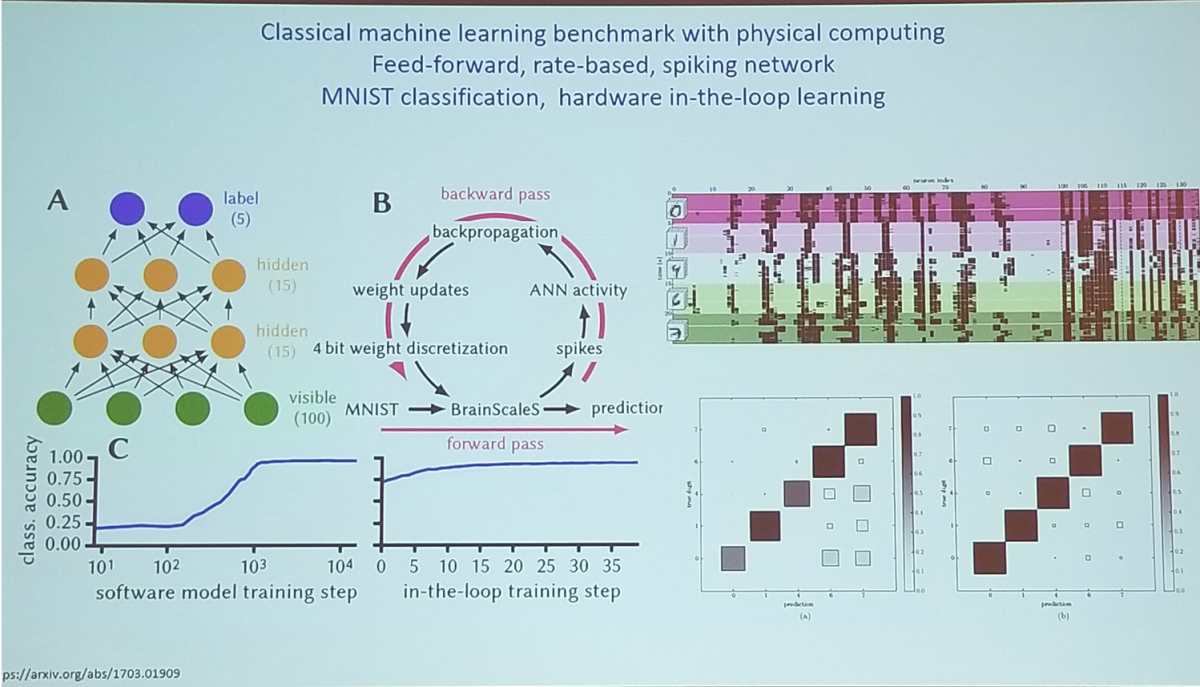
Prof. Karlheinz Meier (Heidelberg University) Continuously Learning Neuromorphic Systems with High Biological Realism, Back-Propagation Cycle
- Spiking Boltzmann machines: learn internal stochastic model of input space: generate or discriminate
- Stochasticity comes from where?
- external noise source?
- noisy components?
- ongoing network spiking activity!
- Running functional networks is noise for another network.
- Arxiv Paper: Deterministic networks for probabilistic computing
- Device variability: good or bad? reviewed study where spiking neural network parameters were varied.
- use or reduce?
- ignore or calibrate?
- important to understand for very deep sub-micron and nano devices!
- Biological self-organization and learning introduce useful variability
- Next: brainscalesS-2: local learning, homeostasis, dendritic computation
- The HICANN-X Chip (next generation BrainsScalesS)
- Embedded SIMD plasticity processing unit (PPU) (see slide pic)
- example shown to learning a target firing rate
- parallel adjustment of neuron parameters.
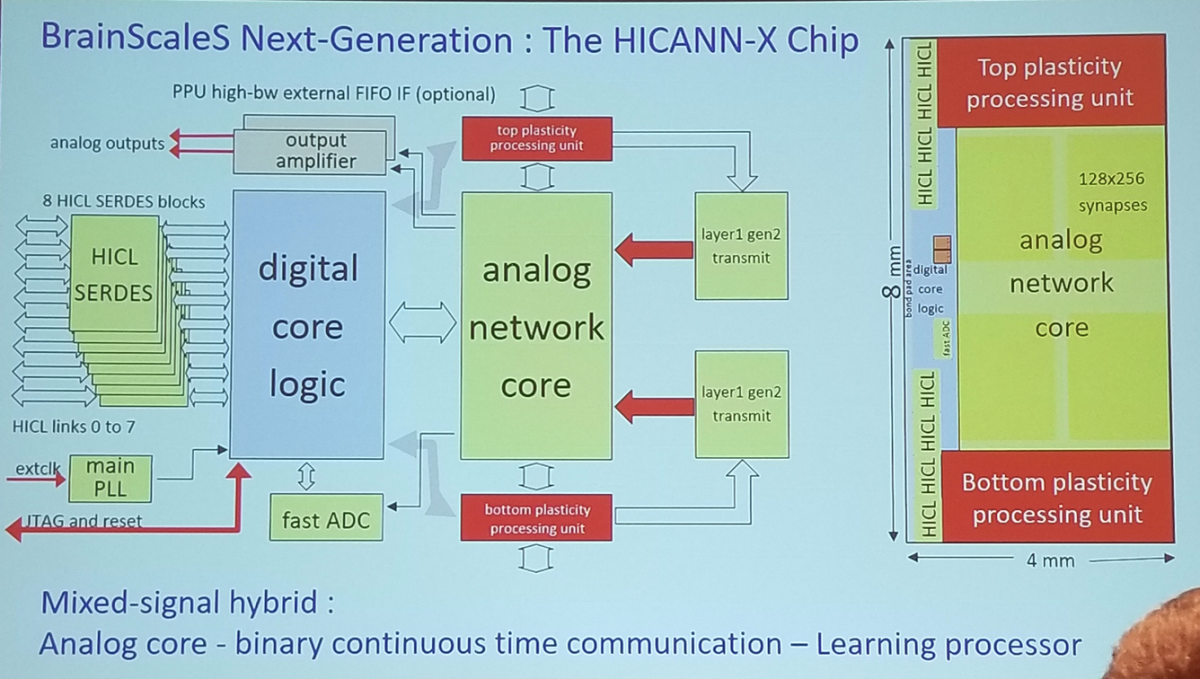
BrainScaleS Next-Generation : The HICANN-X Chip
- Backpropagation activated calcium (BAC) firing for feature binding and recognition
- Active dendrites examples
- Design of a 5000 wafer system underway
A Spike-Timing Neuromorphic Architecture
Aaron J. Hill (Sandia National Laboratories)

Aaron J. Hill (Sandia National Laboratories)
A Spike-Timing Neuromorphic Architecture
- Challenges for neuromorphic hardware:
- Low computation power
- Large population of neurons
- Real time learning
- High fan in
- Temporally coded information
- Spiking temporal processing unit
- Support high fidelity spike timing dynamics
- Simple leaky integrate and fire neuron model with 3 parameters
- leak rate
- Temporal buffer for synaptic delays
- Supports arbitrarily connected networks with configurable weights
- Large off chip memory contains all synaptic information
- pre synaptic neuron designator
- synaptic weight
- synaptic delay
- post-synaptic neuron designator
- Spike transfer structure “the heart of the system”
- spike transfer structure communicates directly to the neuronal processing units
- “LIF” neuron equations, taking into consideration the temporal buffer
- Output spike consolidation
- three-stage consolidator
- pipelined efficiency
- each stage operates in parallel
- number of stages is a parameter
- Hardware development
- Nallatech 385A FPGA Accelerator Card
- 2048 neurons in first test bed
- think they can get 4096, will take manual place and route
- 32 deep parallel buffer
- 16MB of synapse memory
- 18 bits per weight
- 6 bits per delay
- 8 bits post synaptic neuron
- 2048 X 2048 total synapses
- Power measurements on Nallatech 385A
- ~21 nJ per event for 2048 to 32 neurons
- (only looked at dynamic power, wanted to remove FPGA overhead)
- Software:
- uses home grown neural modeling tool: “neurons to algorithms”
- object oriented
- declarative, not procedural
- parts are inheritable and extensible
- back end designed for the STPU
- Liquid state machine was tested
- “can increase accuracy by expanding spike information across time”: synaptic response functions
- reviewed effects of performance on various transfer functions
- STPU results on LSM
- audio signals dataset post processed into cepstral coefficients
- 87.3% accuracy on zeros
- 84.6 accuracy on ones
- Particle Image Velocimetry
- Computing cross-correlation
- Spike Optimization
- Implement fundamental mathematical operations through temporal coding
- spikesort
- spikemin, spikemax, spikemedian
- spikeOpt(median)
- implemented on STPU hardware
- Implement fundamental mathematical operations through temporal coding
Q; how to design how deep to make temporal buffer
A: easy: not a lot of thinking. 32 and 64 come directly from hardware constraint.
Q: what are prospects for coding like an FFT
A: speaker: I dont know. attendant: they are good. we are working on it.
Q: in neural compiler flow, can you use something other than FPGA in mapping. Can representation be standardize.
A: Not sure where we are in this process
Feature Learning using Synaptic Competition in a DynamicallySized
Stanislaw Wozniak (IBM Research, Zurich)

Stanislaw Wozniak (IBM Research, Zurich)
Feature Learning using Synaptic Competition in a DynamicallySized
Neuromorphic Architecture
- “the era of data-centric cognitive computing”
- Challenges: power due to von Neumann architecture
- Goal: rethink computing
- neurommorphic
- phase-change memristors
- Talked about abstraction levels across scale, from molecular to whole brain
- most popular abstraction: artificial neural network
- this work focuses on biologically realistic networks: stateful models that work in time.
- Use model as blue print for hardware.
- spiking neurons, integrate and fire.
- Learning feedback through STDP
- using phase change memory to implement STDP (see slide pic)
- use for mixed analog-digital networks
- digital communication
- simple and reliable (binary spikes)
- analog processing
- efficient using memristors
- Prototype uses crossbar array
- Use single device to store weight
- Use Kirchoffs law for operations
- Talked about going from one layer to two or more layers on MNIST
- Basic overview of learning features using “weather glyfs”
- Synaptic Feature Learning
- WTA/lateral inhibition
- Synaptic competition
- Limited resources related to plasticity
- WTA dynamics at the synapses
- “Representation overflow” by using an “overflow neuron” that has equal low magnitude weights.
- Limitations: by design it limits activation to a single neuron. Results in low F score
- we use WTA for learning, but report activity with WTA disabled

Stanislaw Wozniak (IBM Research, Zurich)
Feature Learning using Synaptic Competition in a DynamicallySized
Neuromorphic Architecture
Q: is the phase reversible?
A: can go between two phases, but high conductance to low conductance is abrupt
Q: how many bits can be stored in memristors?
A: I think 4 bits can be stored.
Q: how faithfully can you reproduce intermediate states
A: we care more about logic of execution. we can read back at accuracy that is sufficient
Q: how to stop learning?
A: never sure what new patterns arrive. ideally never stop learning. Note: have they tested method on real-world noisy data?
Achieving swarm intelligence with spiking neural oscillators
Yan Fang

Yan Fang (University of Pittsburgh)
Achieving Swarm Intelligence with Spiking Neural Oscillators
- motivation: neuromorphic computing
- computational model
- processor architecture
- Motivation: swarm intelligence
- SI algorithm
- ant colony, firefly, particle swarm, bees
- applications
- optimization
- scheduling
- path planning
- Can we bride two models?
- first step: neuromorphic computing for SI algorithm
- generalized swarm intelligence algorithms (see slide pic)
- use leaky integrate and fire model
- prepare an m by n array of neurons to represent each paramter in every agent
Q: any target optimization problem?
A: looking at traveling salesman
Q: have you compared to traditional algorithms?
A: Sort of, compared to other swarm models
Energy Efficient single flux quantum based neuromorphic computing
Mike Schneider

Michael Schneider (National Inst. of Standards and Technology)
Energy Efficient Single Flux Quantum Based Neuromorphic
Computing
- review of josephson junction
- review of circuit model of JJ
- play around with how FM thickness affects critical current density.
- magnetic nanoclusters in a josephson junction
- “nice analog tunable moment change”
- Makes a claim that large-scale “image net” system would reduce to 1 watt, including cooling.

Michael Schneider (National Inst. of Standards and Technology)
Energy Efficient Single Flux Quantum Based Neuromorphic
Computing
“takes a killowatt to cool a watt”
During Q/A:
1. admitted that driving information into the network would be a major challenge that is not at all a solved problem.
1. did not clearly answer how this would be better than a memristive processor.
Improved Deep Neural Network hardware accelerators basd on non-volatle memory: the local gains technique
Geoffrey Burr
- AI as driven by DNNs
- Image recognition, speech recognition, machine translation
- Multiply-Accumulate is key operation for DNN
- Approach uses pairs of memristor devices for weights/synapses.
- want to do both inference and learning via backprop on-chip
- need highly parallel on-chip circuitry
- “our existing phase change memristor are not symmetrical enough”
- need to invent new RRAM materials
- we need “tricks”. Thats my job: to come up with tricks.
- We are going to have a grid that sort of looks like True North.
- We now can get hardware results which are exactly equivalent to software
- Local Gains Technique
- Attempted to redo previous work and duplicate findings, found it did not match.
- Looked into various reasons why, like node activation function, could not find reason
- Found the reason:
- “I had succeeded with my experiment with a particular configuration, I tried it twenty times and one of those times it worked. I had one weekend left to write the paper, and so I wrote this simulator that wrapped around that one particular configuration and learning rate and hyperbolic tangent space. When the students came back they optimized both of those.”
- Local Gains Technique
- Old technique. related to momentum, found out about it on a Hinton video.
- Encourage weights that have a ‘direction’
- Discourage weights that cant make up their mind.
- Local Gains does not work for typical computer scientists
- too hard to tune parameters.
- may work for PCM engineer, since PCM has a non-linear response in incrementation.
- The issue is that many weights are being pulled up and down, and if those do not balance then you end up in trouble.
- We did a nice study of coefficients, seems tolerant to many settings.
- We have a thing called a “safety margin”.
- (appears related to classification margin)

Geoffrey Burr (IBM Research, Almaden)
Improved Deep Neural Network Hardware Accelerators Based on
Non-Volatile-Memory: the Local Gains Technique
A Comparison Between Single Purpose and Flexible Neuromorphic Processor Designs
David Mountain (US Department of Defense)

David Mountain (US Department of Defense)
A Comparison Between Single Purpose and Flexible
Neuromorphic Processor Designs
- Benchmarks:
- mnist
- CSlite-malware detection application
- very digital, nothing “neuromorphic”
- back end detector like a classifier
- 5800 neurons in 6 layers
- AES-256
- pure digital
- 12500 neurons in 8 layers
- memristor array architecture
- Neuron type is a multiply accumulate with threshold gate neuron.
- Uses differential pair synapses for weights.

David Mountain (US Department of Defense)
A Comparison Between Single Purpose and Flexible
Neuromorphic Processor Designs
- Tile concept, bypass comparators and pass to next tile (’tile feature’).
- Tile design is flexible, since array size is limiting to application
- Also tested hierarchical routing.
- All-to-All (A2A) in a tree architecture (based on functional ASIC design in 90nm)
- Evaluation Methodology
- Calculate the area for each design
- Calculate worst-case timing for each design
- calculate power for each design
- calculate T/W (throughput/watt) and T/A (throughput/area
- Conclusions
- Flexible design using tiles and A2A switch is practical compared to special-purpose design.
- the tile feature clearly provides value
- A2A network is superior to 2D mesh.
In-Memory Execution of Compute Kernels using flow-based memristirve crossbar computing
Dwaipayan Chakraborty
- Objective: automated synthesis of C program, translate to crossbar execution.
- restricted sub-set of lanaguage because you cant do everything with crossbars
- problem: “every crossbar is different”. have to make specialized design for every function
- utilizing snea kpaths for computation
- any boolean formula can be mapped to a crossbar using flow-based computing
- Advantages
- Exploits non-volatility of memristors
- leverages flow through the crossbar structure
- fast & energy efficient in many cases
- Disadvantages
- designing flow-based computing circuits may be computationally hard.
- intuitive understanding of flow-based computing is difficult.

Sumit Kumar Jha (University of Central Florida )
Flow-based Non-volatile Memory Crossbar Accelerators for
Parallel Computations
For more information see this video
VoiceHD: Hyperdimensional Computing for Efficient Speech Recognition
Mohsen Imani (University of California, San Diego)
- Deep learning is changing our lives
- power consumption is out of control
- Lee Sedol is 50,000X more efficient than alpha go
- Energy efficiency
- mobile: battery
- cloud: cost
- Hardware scalability
- Hyperdimensional Computing
- take all images of cats (or any other datatype) and “encode a hypervector”
- each hypervector is a model of cat or dog
- look for similarity in hypervectors
- any data is encoded and compressed
- encoding is reversible (can reconstruct input from encoded vector)
- can be implemented in DRAM
Embedding in Neural Networks: A-priori Design of Hybrid Computers for Prediction
Bicky Marquez (Institute FEMTO-ST)
- Classification using delayed phontonic systems
- generally going to higher dimensional allows linear separation
- if you can satisfy these, you have a reservoir computer:
- approximation property
- separation property
- fading memory property
- Instead using random network, they use a delayed (ring) system
- spoken digit recognition, TI-46 corpus, spoke digits from zero to nine
- only have 1000 neurons, but can achieves a performance of 1 million digit recognitions per second
- predict chaotic system (mackey-glass system)
- predictable up to a time, unpredictable after
- random recurrent neural networks, their system worked better (predicted longer out)
Convolutional Drift Networks for Spatio-Temporal Processing
Dillon Graham (Rochester Institute of Technology)
- large volume of video data is being generated
- current approach are very task-specific, costly to train or both
- hand crafted features are commonly used
- Our approach: develop a new neural net architecture with properties
- capable of video activity classification
- general architecture
- minimal training cost
- classification performance competitive with SoTA
- Experiment
- can our new approach perform competitively?
- task: video level activity classification
- data: two first person video datasets
- Combine deep learning and reservoir computing to build a powerful and efficient NN architecture for spatiotemporal data
- observation: all reservoirs converged to same accuracy, but bigger reservoir converged faster
A New Approach for Multi-Valued Computing Using Machine
Learning
Wafi Danesh (University of Missouri, Kansas City)
- moving beyond CMOS
- emergence of an array of devices to continue scaling
- need to leverage intrinsic properties
- beyond CMOS device have unique intrinsic characteristics
- more than a switch
- analog/multi state
- ultra low power
- inherently non volatile
- different domains (magnetic/electric/magnetoelectric
- Proposed MVL (multi-valued logic) synthesis approach
- Random MVL function decomposed to a set of linear equations
- Adaptable to any technology
- Scaled with circuit size
- New MVL algorithm
- 3 steps
- domain selection
- linear regression
- pattern matching
- 3 steps
- Quaternary Multiplier example
Thursday Nov. 9
On Thermodynamics and the Future of Computing
Todd Hylton (University of California, San Diego)

Todd Hylton (University of California, San Diego)
On Thermodynamics and the Future of Computing
- A different way to think about what we do in the field
- how we might really reboot computing in a different way
- The primary problem is that computers cannot organize themselves
- they have narrow focus, rudimentary AI capabilities
- Our mechanistic approach to the problem
- machines are the sum of their part
- machines are disconnected from the world except hough us
- The world is not machine
- Thermodynamic Computing Hypothesis
- Why Thermodynamics?
- its universal
- its temporal
- its efficient
- Thermodynamics drives the evolution of everything
- Thermodynamic evolution is the missing, unifying concept in computing (and many other domains)
- Electronic systems are well suited for thermodynamic evolution
- Thermodynamics should be the principle concept in future computing systems
- Review of thermodynamics in closed and open systems
- Examples of self organization in nature (Alex Nugent’s slide from DARPA days)
- Arbortron video from Stanford
- Life and modern electronic systems comparison

Todd Hylton (University of California, San Diego)
On Thermodynamics and the Future of Computing
- Thermodynamic Evoltuion Hypothesis
- Thermodynamic evolution supposes that all organization spontaneously emerges in order to use sources of free energy in the universe and that there is competition for this energy.
- Thermodynamic evolution is second law, except that it adds the idea that in order for entropy to increase an organization must emerge that makes it possible to access free energy.
- The first law of thermodynamics implies that there is competition for free energy
- Basic proposed demonstration architecture
- evolvable cores in a network that evolve to move energy from source to sink
- Thermodynamic Bit review
- Related ideas
- Free energy principle
- Thermodynamics of Prediction
- Causal Entropic Forcing
More information on Thermodynamic Computing
A Unified Hardware/Software Co-Design Framework for
Neuromorphic Computing Devices and Applications
James Plank (University of Tennessee, Knoxville)

James Plank (University of Tennessee, Knoxville)
A Unified Hardware/Software Co-Design Framework f
- Software Core
- spiking, highly recurrent NN
- implements common functionality or provides and interface for other components to implement
- Application Device operations
- load network
- serialize network
- apply input spikes
- read output spikes
- run
- “Applications want to use numerical events, devices want to use spikes”
- the core provides support for converting application<->device
- Devices/Architectures
- NIDA
- DANNA
- mrDANNA
- Applications
- Control
- Classification
- Security
- Micro-Applications
- Mr. DANNA
- Halfnium Oxide devices
- Differential Pair memristors (2-1 configuration)
- Cadence-Spectre simulations
- 8 synapse neurons
Impact of Linearity and Write Noise of Analog Resistive Memory Devices in a Neural Algorithm Accelerator
Robin Jacobs-Gedrim (Sandia National Laboratories)

Robin Jacobs-Gedrim (Sandia National Laboratories)
Impact of Linearity and Write Noise of Analog Resistive
Memory Devices in a Neural Algorithm Accelerator
- Example of Google deep learning study
- energy/space comparison
- Review of matrix vector multiply with crossbar
- Symmetry/Asymmetry of pulsing incrementation of memristors
- How much effect does this have on accuracy?
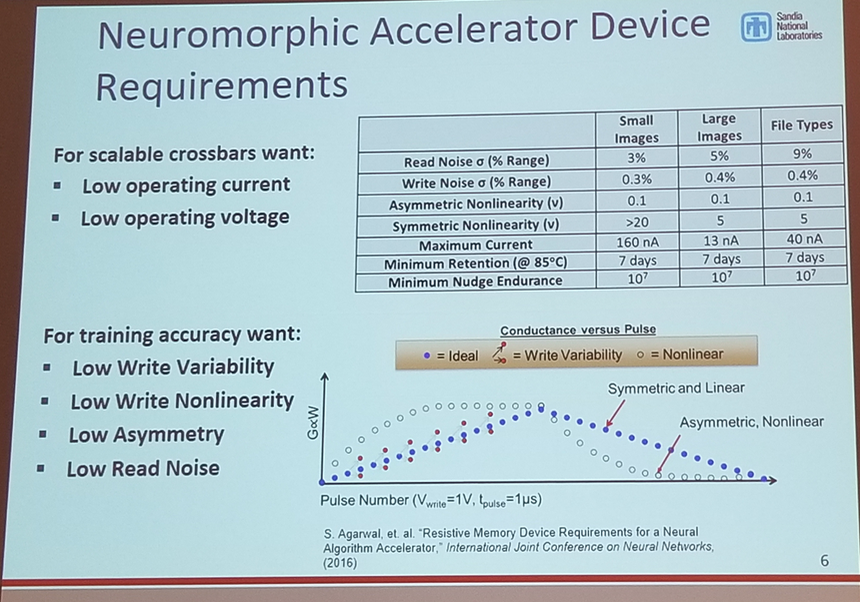
Robin Jacobs-Gedrim (Sandia National Laboratories)
Impact of Linearity and Write Noise of Analog Resistive
Memory Devices in a Neural Algorithm Accelerator
Paper: Resistive memory device requirements for a neural algorithm accelerator
- Comparison of various types of memristors
- SiO2-Cu
- TaOx
- Ag-Chalcogenide varient (likely from ASU?)
- All devices had a nonlinear response that negatively impacted accuracy
- TaOx has lowest noise
- High resistance devices fabricated with an “Al2O3 Bilayer”
- integrated tunneling barrier to increase resistance
- devices needed to be formed
- poor/noisy incrementation response
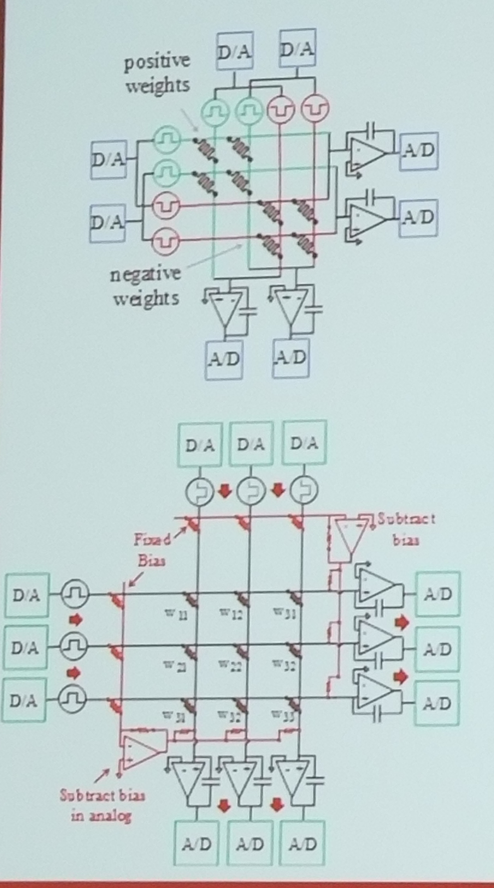
- Differential pair memristor representation
Robin Jacobs-Gedrim (Sandia National Laboratories)
Impact of Linearity and Write Noise of Analog Resistive
Memory Devices in a Neural Algorithm Accelerator
An Energy-Efficient Mixed-Signal Neuron for Inherently ErrorResilient
Neuromorphic Systems
Baibhab Chatterjee (Purdue University)

Baibhab Chatterjee (Purdue University)
An Energy-Efficient Mixed-Signal Neuron for Inherently ErrorResilient
Neuromorphic Systems
- Can we reduce Multiply Accumulate (MAC) energy by 100X?
- what are the Bottlenecks? Could Be:
- energy for computation
- energy for communication
- memory fetch energy
- architecture/algorithms
- Digital MAC Review
- number of transistors increase quickly as number of bits increases
- power at low frequency is dominated by leakage
- high frequency is dynamic power
- Mixed signal MAC
- 1000X better at low frequency, 100X at higher frequency
- higher noise, non-linearities are tradeoffs

Baibhab Chatterjee (Purdue University)
An Energy-Efficient Mixed-Signal Neuron for Inherently ErrorResilient
Neuromorphic Systems
- “Noise Factor” analysis developed and used to evaluate in simulations against multiple benchmarks, relating noise factor to performance degredation.
Borrowing from Nature to Build Better Computers
Prof. Luis Ceze (University of Washington)
- Molecular Data Storage
- Stored “this too shall pass” video in DNA, and other stuff related to DNA as a storage medium.
Rebooting the Data Access Hierarchy in Computing Systems
Wen-mei Hwu (University of Illinois, UrbanaChampaign)
- data access challenges
- IBM Illinois Erudite project
- The reason some apps cant be run on GPU is a data access problem.
- Volta/HBM2, 900GB/s bandwidth,225 Giga SP operands/cycle
- each operands must be used 62.3 times once fetched to achieve peak FLOPS rate
- sustain<1.6% of peak without data reuse
- Volta-Host DDR3
- operands must be used 700 times once fetch to achieve peak FLOP
- sustain<.14% peak without data reuse
- Volta-FLASH, 16GB/S PCIe3
- operands must be used 3507 times once fetched to achieve peak FLOPS
- sustain .03% of peak without data reuse
- Large Problem challenge
- solving larger problems motivates continued growth of computing capability
- inverse solvers for science and engineering apps
- matrix factorization and graph traversal for analytixs
- as problems size grows
- fast, low complexity algorithms win
- sparsity increases, iterative methods win
- data reuse diminished
- solving larger problems motivates continued growth of computing capability
- Erudite Project
- Work done at IBM Illinois C3SR
- computation types
- low-complexity iterative solver algorithms
- graphs analytics
- inference, search, counting
- large cognitive application
- large multi-model classifiers
- to achieve performance:
- elimination of file-system software overhead for engaging in large datasets
- placement of computation appropriately in the memory and storage hierarchy
- highly optimized kernel synthesis
- collaborative heterogeneous acceleration
- Step 1: remove file system from data access path, get ride of storage
- Step 2: place NMA compute inside memory system, 100+ GFLOPS NMA compute into DDR/Flash memory system (~10TBs)
- Erudite NMA board 1.0
- develop a principled methodology for acceleration
- throughput proportional to capacity
- 1 GFLOPS/10GB sustained
- 100 GFLOPS sustained
- Erudite NMA board 1.0
- Step 3: collaborative heterogeneous computing (Chai)
- Unacceptable latency moving data between CPU and GPU.
- Research Agenda
- Package-level integration
- optical interconnects in package?
- collaboration support for heterogeneous devices
- virtual address translation
- System software revolution
- persistent objects for multi-language environments
- directory and mapping of very large persistent objects
- power consumption in memory
- much higher memory level parallelism needed for flash based memories
- latency vs. throughput oriented memories
- Package-level integration
- Conclusion and Outlook
- drivers for computing capabilities
- large-scale inverse problems with natural data inputs
- machine learning based applications
- Erudite cognitive computing systems project
- removing file system bottleneck from access paths to large datasets
- placing compute into the appropriate levels of the memory system hierarchy
- memory parallelism proportional to the data capacity
- collaborative nms execution with CPU and GPUs
- >100x improvement in power efficiency and performance
- drivers for computing capabilities
“sparse is more of our target than dense”
The Superstrider Architecture: Integrating Logic and Memory towards non-von Neumann Computing
Sriseshan Srikanth (Georgia Institute of Technology)

Sriseshan Srikanth (Georgia Institute of Technology)
The Superstrider Architecture: Integrating Logic and Memory
towards non-von Neumann Computing
- superstrider: geared toward processing sparse data streams
- moving data is expensive, time and energy
- logic-memory integration,
- vertical integration with 3D stacking
- micron hybrid memory cube
Sriseshan Srikanth (Georgia Institute of Technology)
The Superstrider Architecture: Integrating Logic and Memory
towards non-von Neumann Computing
- superstrider
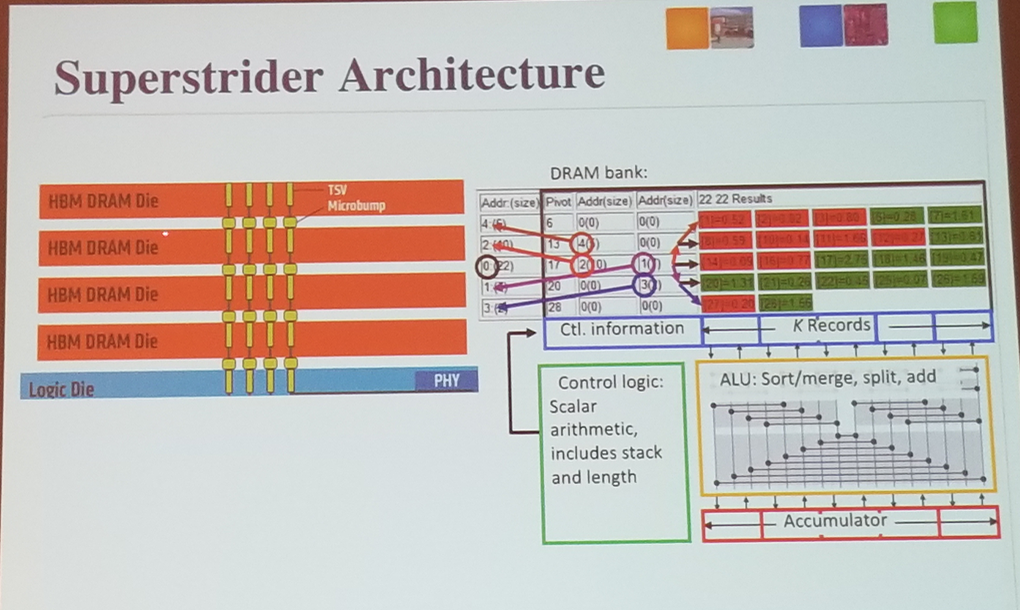
- acceleration reduction of sparse data streams using logic-memory 3D integration
- accumulation of phase of SpGEMM
- near perfect cache mis-rate for sparese data
- data organized in binary tree
- key principles
- memory rows organized as a binary tree with k records (sorted by key_ and a pivot(key) per row
- memory access and computation granularity:
- 1 memory row of sorted records
- SIMD style operation tightly integrated with wide memory words
- Sorted invariant
- two N/2 length pre-sorted vectors can be merged in log2(N) stages
- novel algorithms
- Long examples of storing sparse data pairs given
NNgine: Ultra-Efficient Nearest Neighbor Accelerator Based on In-Memory Computing
Mohsen Imani (University of California, San Diego)

Mohsen Imani (University of California, San Diego)
NNgine: Ultra-Efficient Nearest Neighbor Accelerator Based on
In-Memory Computing
- Big data processing with general purpose processing
- can todays system process big data?
- [cores/memory with separation shown]
- Cost of memory access is much higher than computation
- DRAM read: 640pJ
- 8b add: .03pJ
- DRAM consume 170x more energy than FPU mult
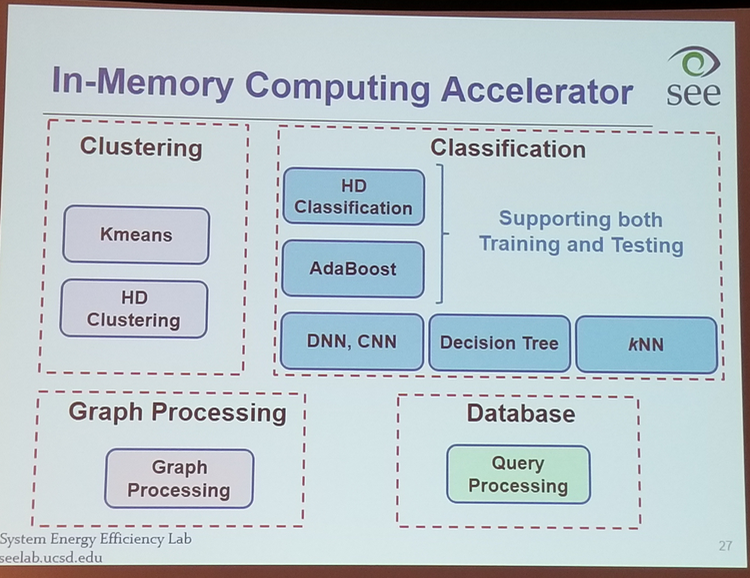
- Processing in memory (PIM)
- perform a part of computation tasks inside the memory
- Supporting in-memory operations
- bitwise
- OR, AND, XOR
- Search operation
- nearest search
- clustering
- classification
- database
- Addition Multiplication
- matrix multiplications
- deep learning
- bitwise
Mohsen Imani (University of California, San Diego)
NNgine: Ultra-Efficient Nearest Neighbor Accelerator Based on
In-Memory Computing
- Related publications

Mohsen Imani (University of California, San Diego)
NNgine: Ultra-Efficient Nearest Neighbor Accelerator Based on
In-Memory Computing
- Crossbar NOR operation example
- voltage divider with lower elements encoding each input. if any element is on, will 1. pull down voltage and you get OR logic operation.
- NORE based addition
- Fast In-Memory Addition
- add multiple numbers in four stages
- additions in the same stage of execution are independent and can occur in parallel
- speed up comes at th cost of increased energy consumption and number of writes in memory
- last state dominates the addition latency.
- add multiple numbers in four stages
- NNgine: KNN accelerator
- nearest neighbor search accelerator
- performing the search operation inside the memory next ot DRAM
- kNN review
- kNN in GPU performance review, execution time, cache hit, dataset size
- Content addressable memory (CAM)
- Nearest Neighbor search
- find similar rows in parallel using hammming distance criteria
- count HDs based on timing characteristics of discharging current
- Nearest Neighbor search
- NNAM Architecture overview
1: DVS: applies voltage over scaling to block
any row with the higher match bits discharges first
2: NN detector: sense the number of matched lines and notify the controller
3: Controller dynamically adjust voltage, based on the number of discharge row - Use a simple analog design to sample match lines, accumulate currents, compare to thresholds
- NNgine energy improvement: 349X
- AdaBoost acceleration
Socrates-D: Multicore Architecture for On-line Learning
Tarek Taha (University of Dayton)
- have a system that can learning continuously at low power. uses:
- robotics
- personal devices
- low power deployed systems
- what is done now: Continuous training on cloud
- requires network access
- privacy risk
- slow and high energy
- Multicore near memory computations
- both learning and inference capability
- overview of backprop
- on the forward pass, the forward matrix is large. in backward pass we have to access in transpose form
- to handle transpose matrix we have two weight matrix memories for forward and transposed forms
- dual matrix approach not necessary, but runtime is much longer and power consumption is lower.
- Static Routine and Dynamic Routing implemented in simulations.
- Static Routing is significantly more efficient, but a problem:
- connections are dedicated, which will block routining through cores.
- solved this problem with time multiplexing
- distribute large networks across cores by partitioning network and using another core to add partial sums from partitioned cores.
Computing Based on Material Training: Application to Binary
Classification Problems
Eleonore Vissol-Gaudin (Durham University)

Eleonore Vissol-Gaudin (Durham University)
Computing Based on Material Training: Application to Binary
Classification Problems
- Use evolutionary algorithms
- explore and exploit unconfigured materials
- perform a computation
- computer-hardware interface (custom made)-material
- materials have a non-linear input output behavior
- non-biological material is considered better
- used carbon nanotubes dispersed in liquid crystal
- treat training as an optimization function
- define an objective function
- define a set of decision variables
- supervised learning approach
- divide dataset into training and verification
- send the training set to black box
- modify configuration signals
- signal are controlled by an evolutionary algorithm
- use custom motherboard “evolvable motherboard”
- liquid crystal provides non-conductive medium for carbon nanotubes, which form percolation paths between electrodes during applicaiton of voltage across electrodes

Eleonore Vissol-Gaudin (Durham University)
Computing Based on Material Training: Application to Binary
Classification Problems
- evolutionary algorithm
- stochastic
- derivation-free
- iterative
- Differential Evolution
- selection, crossover, mutation
- Questions they want to answer:
- can the material classify dataset restrain after being retrained
- can it provide solution comparable to ML techniques
- use artificial binary 2D datasets
- linear
- non-linear
- used Fischer criteria to gauge complexity of classification
- Main observations
- contribution of material state to classifier non-negligible
- the same sample can be retrained for at least two problems
- modification in the state do not fully destroy original solution
- applied to two data sets
- worse on mamographic mass dataset
- bupa liver disorder data are comparable to NN
Nonlinear Dynamics and Chaos for Flexible, Reconfigurable
Computing
Benham Kia (North Carolina State University)
- New reconfigurable hardware that be instantly reprogrammed to implement many different functions
- nonlinearity as a source of variability
- simple nonlinear system can exhibit diverse, complex behaviors
- Example: songbird
- reference songbird paper: M. Fee, et al, Nature 395 1998
- the vocal organ of birds are nonlinear cavity that produce complex song.
- by changing the input parameters, circuit produces different songs
- Chaos is not random
- Chaos=infinite number of unstable “modes” without any stable condition
- Paper title: “a simple nonlinear circuit contains an infinite number of functions”
- reference table 1 in paper.
- “a dynamic system is nothing more than an embodiment of a function”
- Used Mosis to fabricate a series of circuits (four generations), starting in 2014.
- It can implement a different instruction at each clock cycle with special thanks to instant re programmability
- enabled application: analog to digital conversion and noise filtering
- analog input–>(control)–>digital sequence
- Focus application:
- extend typical signal processing chain to:
- filter noise from analog signal
- convert to analog signal to digital
- perform reconfigurable computing
- implement multiplication efficiently
- evolve or adapt
- all with minimal power and silicon area
- extend typical signal processing chain to:
A Thermodynamic Treatment of Intelligent Systems
Natesh Ganesh (University of Massachusetts, Amherst)
- what are the thermodynamic conditions under which physical systems learn?
- discussed the difference between ‘self assembly’ (non-dissipative) vs ‘self-organized’ (dissipative, non-equilibrium)
- if you remove energy source, the structure decays in a self-organized system
- review of fluctuation theorems for non-equilibrium thermodynamics dissipation in finite state automata
- what is the relationship between dissipation and intelligence?
- intelligence: can use past input to prediction future inputs
- average change in total entropy of system and bath = fluctuations about the mean
- under the right conditions: learning is synonymous with the energy efficient dynamics of the system
- thermodynamic computing
- a new engineering paradigm that will combine thermdynamics and information theory
- highlighted UCLA silver nanowire work.










Leave a Comment