[popupwfancybox id=”7″]
Overview
The Knowm technology stack bridges the levels of abstraction required to realize an AI processor based on memristor synapses, connecting the dots from nanotechnology to applications.
Memristors are an enabling nanotechnology for a new AI computing technology stack
Knowm M-SDC memristors have openly demonstrated all physical properties required of our technology stack, including the important manufacturing properties of low cost, high yields and long shelf-life.

Knowm memristor array chip
Differential pair memristors form a new type of synaptic computing element

Differential pair memristor synapse configurations
A collection of synaptic elements form neuron-like computing circuits
Learning/programming and logic/inference operations reduce to the activation of a low-voltage analog circuit, eliminating memory-processing communication, improving speed and greatly reducing energy dissipation.
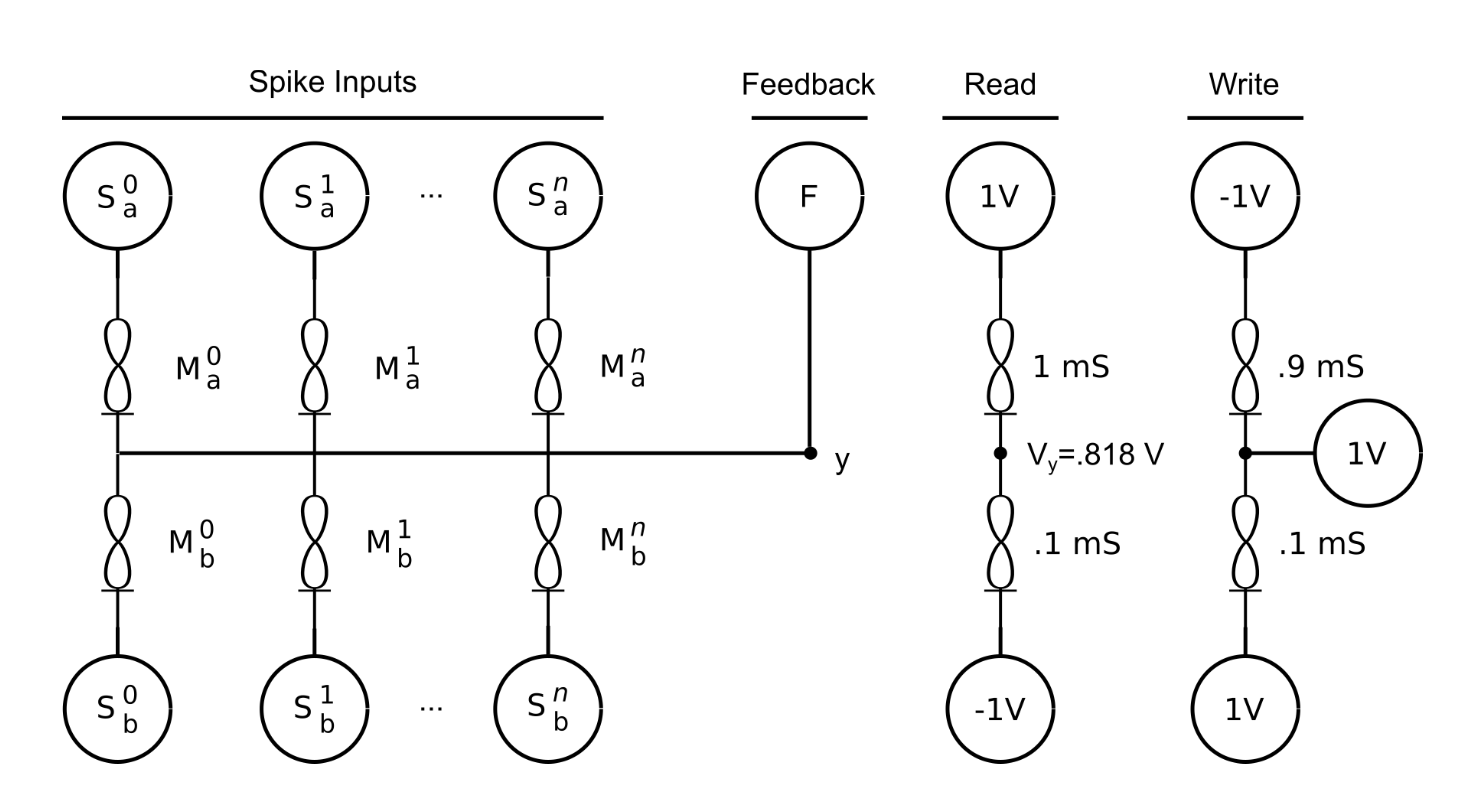
2-1 configuration differential pair memristor neuron
Information is encoded by integer tensor streams
A spike stream is a temporal sequence of spike patterns. A spike pattern is a collection of integers in a defined spike space. A spike tensor is a multi-dimensional array of spike streams.
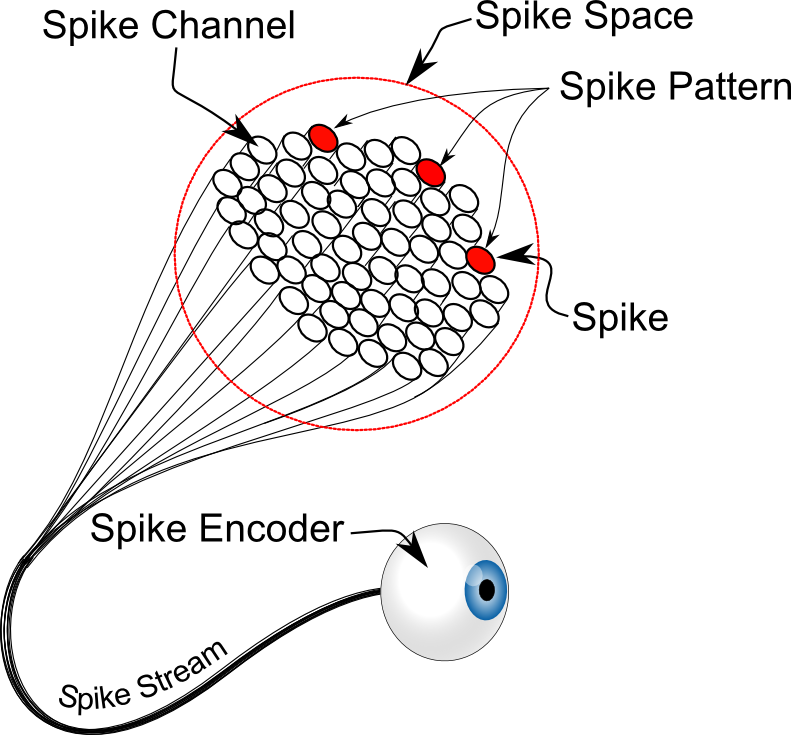
Integer Spike Encoding
Synaptic cores are collections of synapses that are partitioned into one or more neurons
Collections of addressable differential-pair memristor synapses form the primitive mixed memory-processing core from which learning/programming and inference/logic operations are realized. Many core types are possible based on synaptic addressing method and topology restrictions. Cores can be emulated by existing computing technology.
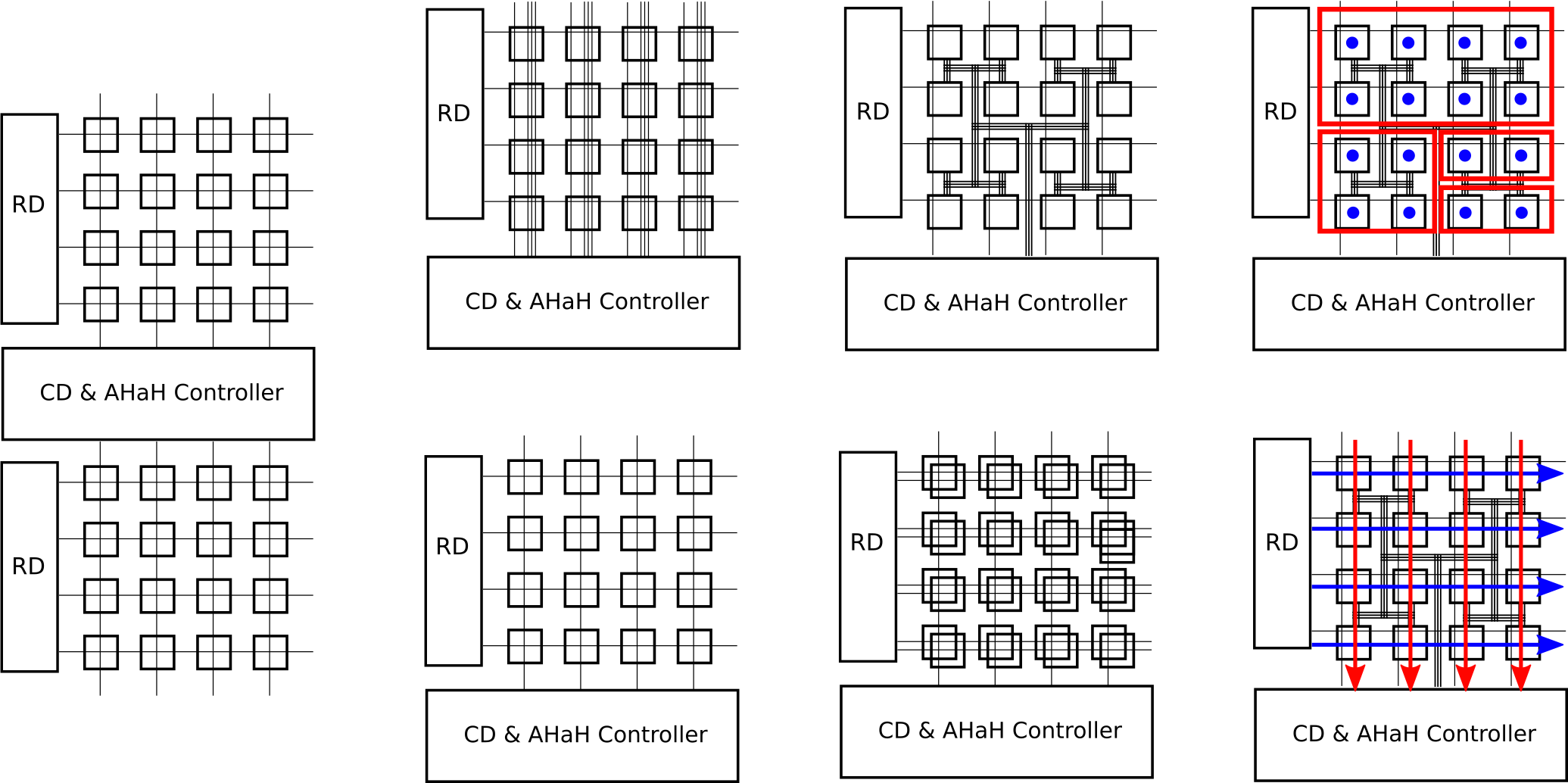
Example synaptic core types
Synaptic cores execute instructions on co-activated synaptic elements
Elemental instructions define electrical drive patterns across the terminals of co-activated memristor synapses. These instructions can result in modification of the synaptic state and are used for both learning/programming and inference/logic operations. Different underlying synapse circuits (1-2, 2-1, 1-2i, 2-1i) require different drive patterns to achieve the same functional effect, for example to increment the synaptic state high or low, decay its magnitude, etc.
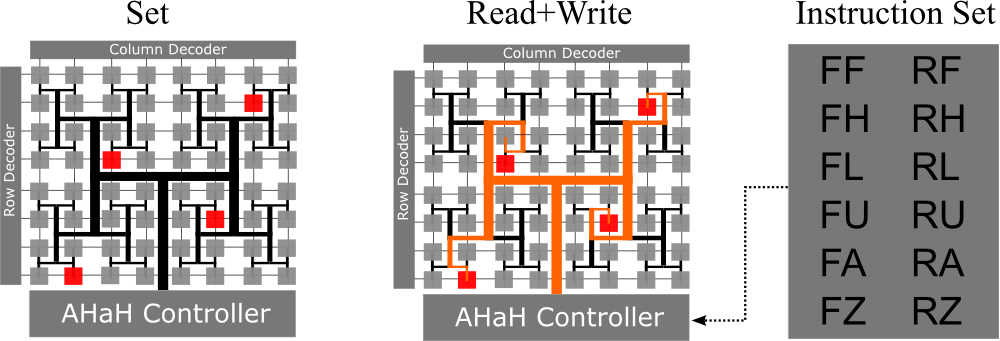
Synaptic core instruction set
Operators are programs that execute synaptic instructions and other logic

Operator Interface

Example synaptic core instruction set routine
Graphs are digraphs of operators
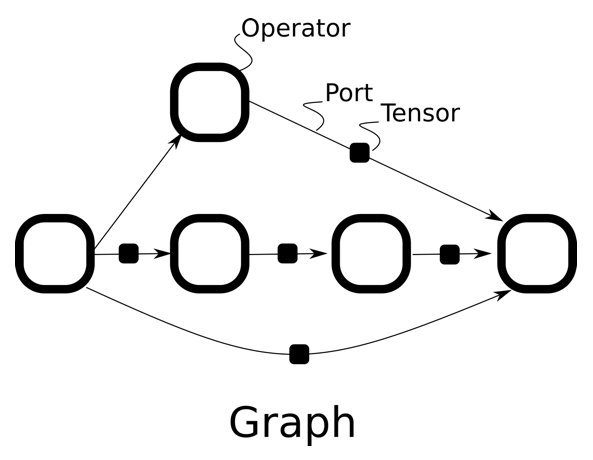
Operator Graph

Example Knowm Graph
Graph Servers are network end-point resources for applications

Knowm Graph Server
Knowm anomaly is an example application built on the knowm technology stack
Some of these elements including guiding philosophy are further elaborated in this paper: https://arxiv.org/abs/1406.5633 / Taylor and Francis.










Leave a Comment