Abstract
We present a high level design of kT-RAM and a formal definition of its instruction set. We report the completion of a kT-RAM emulator and the successful port of all previous machine learning benchmark applications including unsupervised clustering, supervised and unsupervised classification, complex signal prediction, unsupervised robotic actuation and combinatorial optimization. Lastly, we extend a previous MNIST hand written digits benchmark application, to show that an extra step of reading the synaptic states of AHaH nodes during the train phase (healing) alone results in plasticity that improves the classifier’s performance, bumping our best F1 score up to 99.5%.
Introduction
Because of its superior power, size and speed advantages over traditional von Neumann computing architectures, the biological cortex is one of Nature’s structures that humans are trying to understand and recreate in silicon form. The cognitive ability of causal understanding that animals possess along with other higher functions such as motor control, reasoning, perception and planning are credited to different anatomical structures in the brain and cortex across animal groups. While the overall architecture and neural topology of the cortex across the animal kingdom may be different, the common denominator is the neuron and its connections via synapses. In this paper, we present a general-purpose neural processing unit (NPU) hardware circuit we call ThermodynamicRAM that provides a physical adaptive computing resource to enable efficient emulation of functions associated with brains and cortex. The motivation for this work is to satisfy the need for a chip where processor and memory are the same physical substrate so that computations and memory adaptations occur together in the same location. For machine learning applications that intend to achieve the ultra-low power dissipation of biological nervous systems, the shuttling of bits back and forth between processor and memory grows with the size and complexity of the model. The low-power solution to machine learning occurs when the memory-processor distance goes to zero and the voltage necessary for adaption is reduced. This can only be achieved through intrinsically adaptive hardware. Other experts in the field have also expressed the need for this new type of computing. Traversa and Ventra recently introduced the idea of ‘universal memcomputing machines’, a general-purpose computing machine that has the same computational power as a non-deterministic Universal Turing Machine but also exhibiting intrinsic parallelization and information overhead. Their proposed DCRAM and other similar solutions employ memristors, elements that exhibit the capacity for both memory and processing. They show that a memristor or memcapacitor can be used as a subcomponent for computation while at the same time storing a unit of data. A previous study by Thomas et al. also argued that the memristor can better be used to implement neuromorphic hardware than traditional CMOS electronics. In recent years there has been an explosion of worldwide interest in memristive devices, their connection to biological synapses, and use in alternative computing architectures. Thermodynamic-RAM is adaptive hardware operating on the principles of ‘AHaH computing’, a new computing paradigm where processor and memory are united. The fundamental building blocks it provides are ‘AHaH nodes’ and ‘AHaH synapses’ analogous to biological neurons and synapses respectively. An AHaH node is built up from one or more synapses, which are are implemented as differential memristor pairs. Spike streams asynchronously drive coactivation of synapses, and kT-RAM’s instruction set allows for specification of supervised or unsupervised adaptive feedback. The co-active synaptic weights are summed on the AHaH node’s output electrode as an analog sum of currents providing both a state and a magnitude. While reverse engineering the biological brain was not the starting point for developing AHaH computing, it is encouraging that the present design shares similarities with the cortex such as sparse spike data encoding and the capacity for continuous on-line learning. Much like a graphical processing unit (GPU) accelerates graphics, kT-RAM plugs into existing computer architectures to accelerate machine learning operations. This opens up the possibility to give computer hardware the ability to perceive and act on information flows without being explicitly programmed. In neuromorphic systems, there are three main specifications: the network topology, the synaptic values and the plasticity of the interconnections or synapses. Any generalpurpose neural processor must contend with the problem that hard-wired neural topology will restrict the available neural algorithms that can be run on the processor. In kT-RAM, the topology is defined in software, and this flexibility allows for it to be configured for different machine learning applications requiring different network topologies such as trees, forests, meshes, and hierarchies. Much like a central processing unit (CPU) carries out instructions of a computer program to implement any arbitrary algorithm, kT-RAM is also generalpurpose, in that it does not enforce a specific network topology. Additionally, a simple instruction set allows for various forms of synaptic adaptation, each useful within specific contexts. So far as we currently understand, the kT-RAM instruction set is capable of supporting universal machine learning functions. For an exhaustive introduction to AHaH computing, AHaH nodes, the AHaH rule, and the AHaH node as well as circuit simulation results, machine learning benchmark applications, and accompanying open source code, please refer to a previous paper entitled “AHaH computingFrom Metastable Switches to Attractors to Machine Learning”.
…
Read the entire article in PDF format at http://arxiv.org/pdf/1408.3215v1.pdf.
Select Figures

Fig. 1. Thermodynamic-RAM utilizes standard RAM technology for synaptic activation over a two-dimensional address space (light gray-bordered cells). The fractal H-Tree wire (red) forms a common electrical node (y) for summing the synaptic weights of an AHaH node (neuron) and also for providing a learning/feedback signal. Here an 16 x 16 cell array is shown, but in practice a much larger array containing many thousands of synapses can be fabricated. AHaH node temporal partitioning is achieved by addressing different spaces at different points in time (AHaH nodes A and B).
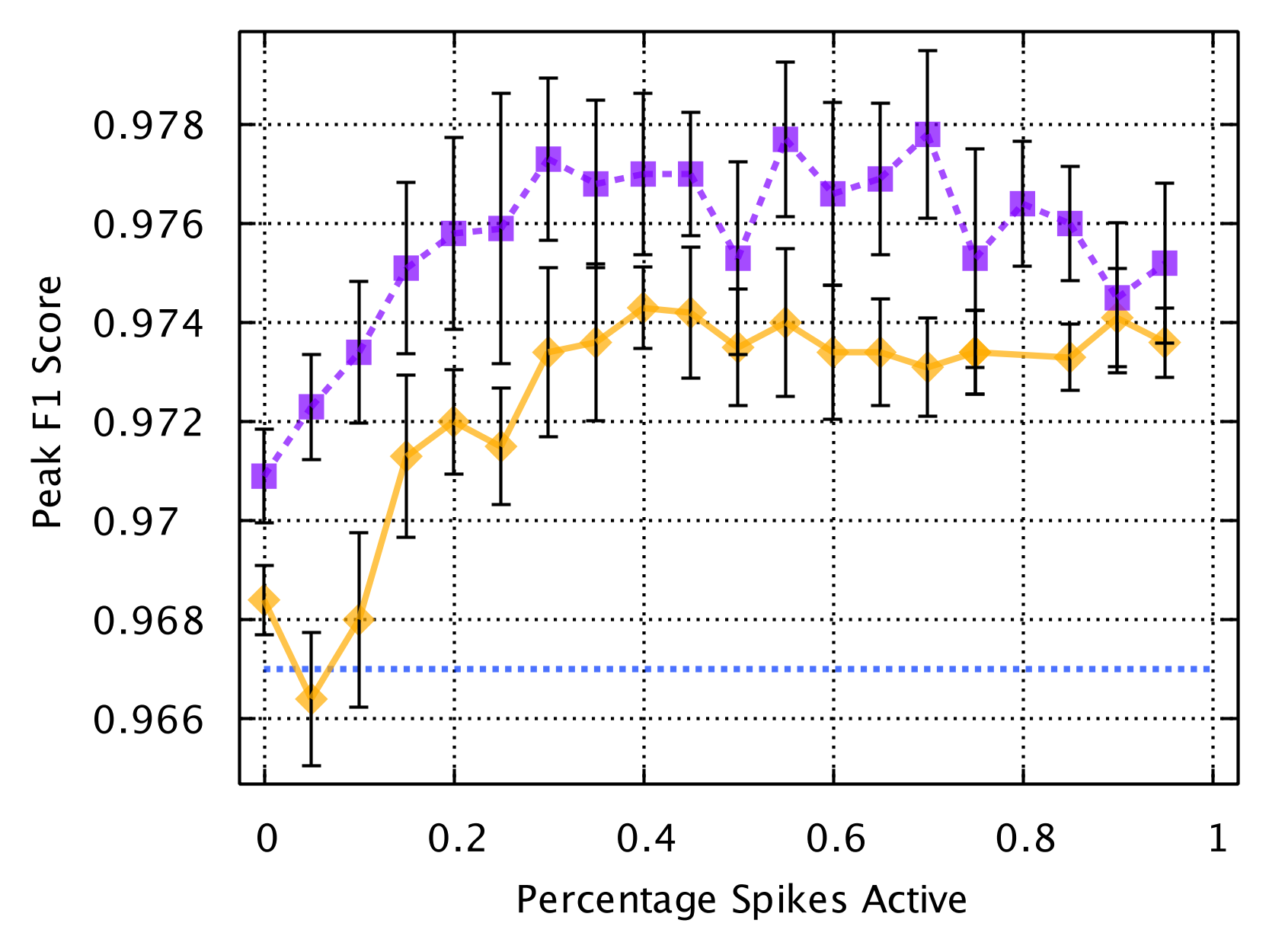
Fig. 4. For each training exemplar in the MNIST classification benchmark, a non-adaptive spike encoder was used to generate a spike encoded input to the kT-RAM classifier. Random subsets of the original spike-encoded input (from 0% to 95%) were generated from the original spike pattern and reclassified (healing), either unsupervised (purple, dashed) or supervised (orange). Average baseline F1 score for 3 epochs was 0.967 (blue, dotted). The results demonstrate that the act of reading the synaptic states of AHaH nodes results in plasticity that improves the classifier’s performance on the test set.










2 Comments
John Alley
You are losing people at the instruction set (Not casual people, people like me who are trying to understand your entire stack. and the implications of hardware that classifies as an act of its respiration on current deep learning architctures that classify but only after omg huge amounts of effort.)
Feels to me that one thing desperately needed in your list of materials is a 15 minute video explanation of the instruction set and how it relates to conventional microcode. In many of the videos you get yahoos talking about this sort of instruction and that sort of instruction and as I review my understanding of your stuff, it is quite clear that that is where you lost me.
Alex Nugent
John, the kT-RAM instruction set defines voltage drive patterns across the selected array of kT-Synapses (differential pairs of memristors acting as synaptic weights). This presentation may help.